RViDeNet-ECBAM
A RAW video denoiser that takes three consecutive noisy Bayer frames and reconstructs the clean RAW of the center frame — with an attention block redesigned for the globally-distributed noise of extreme low light.
Overall structure
The network takes consecutive noisy Bayer RAW frames In[t−1:t+1] and outputs the denoised RAW frame Orawt for the center frame. It is organised into six stages:
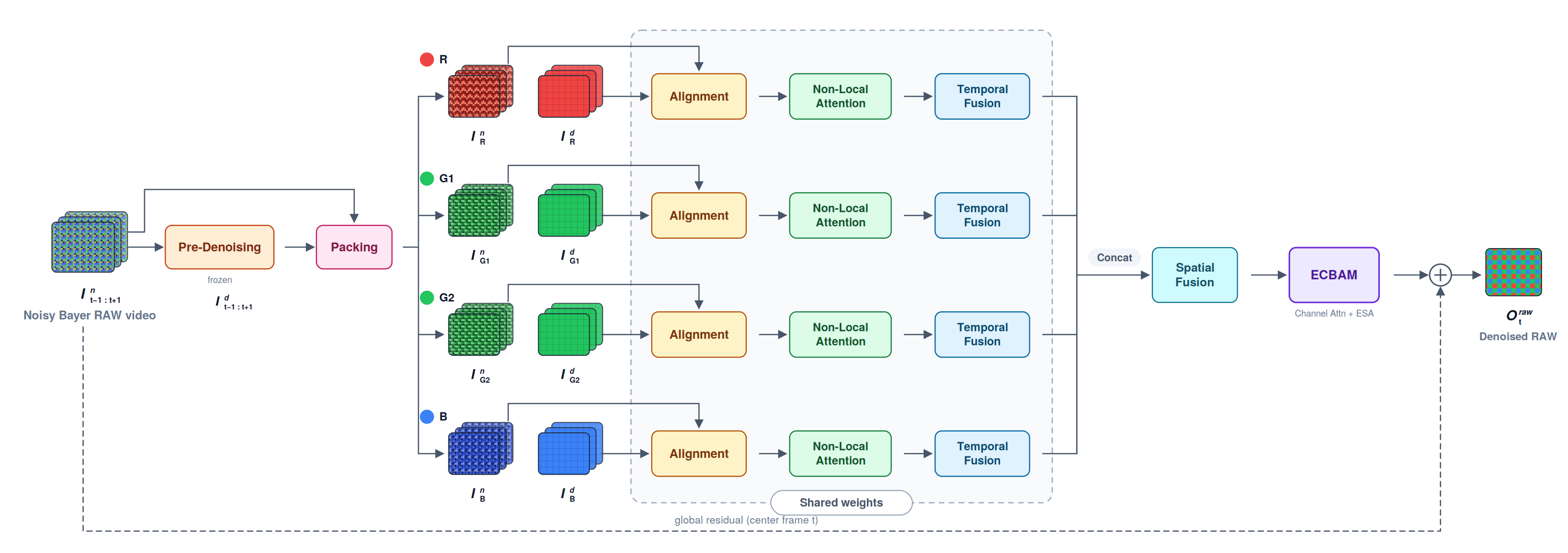
A pretrained, then frozen module lightly denoises the input so that motion/alignment offsets are estimated from clean-ish features, not raw noise.
Noisy and pre-denoised frames are split by Bayer pattern into four colour sub-frames (R, G1, G2, B). For the IMX327 sensor used here the pattern is RGGB.
The four channels run a shared-weight path: pyramidal deformable alignment, global spatio-temporal attention, then confidence-weighted temporal fusion of the three frames.
The fused channels are concatenated and passed through a 10-residual-block reconstruction trunk that exploits cross-channel correlation.
Channel attention + Enhanced Spatial Attention, replacing CBAM's 7×7 spatial attention with a downsampled, large-receptive-field mask.
A final 3×3 conv produces a 4-channel RAW residual; the center noisy frame is added back to yield the denoised RAW output.
Pre-denoising & packing
The noisy RAW frames first pass through a pre-denoising module whose parameters are frozen after pretraining. Its output is not used directly in the final restoration; instead it guides deformable-convolution offset estimation during alignment. In extreme low light, feeding heavy noise straight into offset estimation destabilises frame-to-frame registration, so estimating motion from denoised features makes alignment more reliable.
Packing then splits each noisy and pre-denoised frame into four colour channels following the Bayer layout. Because the IMX327 sensor is RGGB, each frame becomes an R / G1 / G2 / B set of sub-frames fed into per-channel paths.
Per-channel processing
The four packed channels run in parallel through an identical, weight-shared path of three modules:
Alignment
A pyramidal deformable-convolution module aligns neighbouring frames (t−1, t+1) to the center frame. Offsets are estimated from the pre-denoised features but applied to the noisy features, over a 3-level (full / ½ / ¼) coarse-to-fine pyramid that compensates both large and fine motion.
Non-Local Attention
Computes global spatio-temporal correlations between aligned frame features, capturing long-range dependencies that local convolutions miss. Regions whose local information is destroyed by noise can be restored by referencing similar patterns at other positions and in other frames.
Temporal Fusion
Temporal and spatial attention weight the three frames by per-frame reliability and merge them into a single feature map — high weight where alignment is accurate, low weight where alignment error is large — suppressing ghosting in moving scenes.
Spatial fusion & the ECBAM block
The four fused channels are concatenated and passed through Spatial Fusion, a reconstruction trunk of 10 residual blocks. The attention block applied to its output is the heart of this project.
Why CBAM falls short in extreme low light
The original RViDeNet uses CBAM here — channel attention followed by a 7×7-convolution spatial attention. That spatial attention is limited to a 7×7 receptive field. In extreme low light, noise is distributed almost uniformly across the whole frame, and a narrow receptive field cannot reliably tell flat noisy regions apart from the structures that must be preserved.
ECBAM = channel attention + Enhanced Spatial Attention (ESA)
We keep CBAM's channel attention (average/max pooling + shared MLP) but replace the spatial attention with ESA:
- A 1×1 conv reduces channels to ¼ to cut compute.
- Stride-2 conv + 7×7 max-pool (stride 3) heavily downsample the feature map. Convolving on this shrunken map aggregates context from a much wider region of the original resolution with the same kernel size.
- Bilinear upsampling restores resolution; a 1×1-conv skip branched before downsampling is added back to recover fine positional detail.
- A final 1×1 conv + sigmoid produces the spatial attention mask, multiplied element-wise into the input features.
Why it helps
- Wide receptive field. The mask is built on downsampled features, reflecting far more global context than a 7×7 conv — so globally-distributed low-light noise and object structure can be separated by global context, suppressing flat-region noise while preserving edges.
- Cheap. Spatial attention runs on a ¼-channel, low-resolution map, so enlarging the receptive field adds little compute.
- Detail-aware. The 1×1-conv skip restores positional detail lost in downsampling, combining wide context with precise boundaries.
In our experiments, RViDeNet-ECBAM gives consistent PSNR/SSIM gains on every self-captured scene and the best temporal consistency (tOF) among all compared methods — evidence that the wide-receptive-field spatial attention is effective against global low-light noise.
Global residual & output
A final 3×3 convolution turns the ECBAM features into a 4-channel RAW residual, and the center noisy frame is added back as a global residual to form the denoised RAW output Orawt. Learning only the noise residual (rather than the whole signal) stabilises training and passes the input's structure straight through to the output, helping fine-detail preservation.
Changes vs. the original RViDeNet
| Aspect | Original RViDeNet | This project (RViDeNet-ECBAM) |
|---|---|---|
| Attention block | CBAM (channel + 7×7 conv spatial) | ECBAM (channel + ESA) |
| Spatial-attention receptive field | Limited to 7×7 kernel | Greatly enlarged (strided conv + max-pool downsampling) |
| Bayer packing | GBRG (CRVD) | GBRG + RGGB (IMX327) |
| Synthetic noise model | Poisson + Gaussian | Poisson + Gaussian + row noise + quantization noise |
| Fine-tuning LR | Single LR | Layer-wise (backbone 1e−6 / recon·ECBAM·output 1e−5) |
| Inference | CRVD evaluation script | Full-resolution tiled inference pipeline |
Datasets
CRVD and the self-captured low-light RAW set are used for sequential fine-tuning; ReCRVD is held out to test generalization under conditions different from training.
| Dataset | Composition | GT generation | Role |
|---|---|---|---|
| CRVD | 11 indoor scenes × 5 ISO (1600–25600), 55 scenes × 7 frames | Average of repeated noisy RAW per position (ISO 25600: 500-shot avg + BM3D) | Fine-tuning (stage 3-1) |
| Self-captured low-light RAW | 0.1 lux, 12 scenes × 60 frames, IMX327 RAW | ~100-shot average per frame position, no extra post-processing | Fine-tuning + validation (stage 3-2) |
| ReCRVD | 4K-screen re-capture, 120 scenes | High-ISO noisy ×10 + ISO 100 long-exposure clean ×1 | External generalization test |
The self-captured 0.1 lux RAW set is the lab's private, non-public dataset; it is not released.
Three-stage strategy
Training all of the network from scratch on real low-light RAW alone is unstable, so the model first learns basic restoration on synthetic data and is then gradually adapted to real sensor noise. Every stage uses the ECBAM-equipped model.
Stage 1 · Pre-denoising pretraining
The pre-denoising module is pretrained on synthetic noisy–clean pairs (230 clean SID RAW images + Poisson–Gaussian noise) and then frozen. It exists only to give deformable alignment a stable, denoised guide for offset estimation.
Stage 2 · RViDeNet pretraining
Real noisy–clean RAW video of diverse moving objects is hard to capture, so synthetic RAW video is built from four MOTChallenge sRGB clips via image unprocessing, then corrupted with the RAW noise model. The base model is shot noise as Poisson, read noise as Gaussian:
We extend it with row noise and ADC quantization noise observed in real CMOS sensors, narrowing the gap to real sensor-noise distributions. The loss is RAW reconstruction only:
Learning rate starts at 1e−4, drops to 1e−5 after 20 epochs, converging at epoch 33.
Stage 3 · Sequential fine-tuning
Starting from the pretrained model, we fine-tune on CRVD first, then the self-captured 0.1 lux set, on 256×256 patches. The loss adds a temporal consistency term (no sRGB loss):
ℒrec = ‖ Itraw − Otraw ‖1
ℒtmp = ‖ Ôtraw1 − Ôtraw2 ‖1 + γ(‖ Itraw − Ôtraw1 ‖1 + ‖ Itraw − Ôtraw2 ‖1)
Here Ôraw1 and Ôraw2 are two outputs for the same frame from different noisy-sample combinations; forcing them to agree suppresses frame-to-frame flickering. We set λ = 1, γ = 0.1.
- 3-1 · CRVD (LR 1e−5). Adapts the synthetic-trained model to real captured RAW. CRVD's GBRG pattern is packed in G, B, R, G order.
- 3-2 · Self-captured 0.1 lux (layer-wise LR). Final tuning to IMX327 noise, Bayer (RGGB → packed R, G, G, B) and extreme-low-light characteristics. The backbone uses 1e−6 to preserve CRVD-acquired noise adaptation, while the reconstruction trunk, ECBAM and output conv use 1e−5 so adaptation concentrates in the restoration stage.